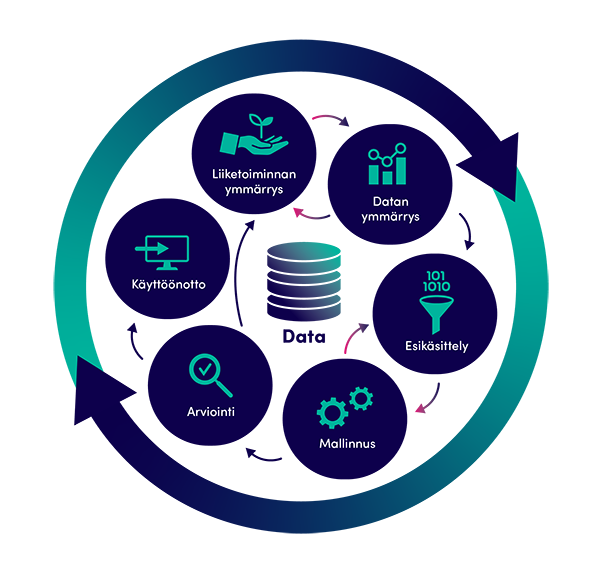
Datavetoisen hankkeen vaiheistus

Yleinen malli datavetoisen hankkeen vaiheista on niin kutsuttu CRISP-DM (Cross-industry standard process for data mining). Kyseessä on kaikille toimialoille tarkoitettu tiedonlouhinnan standardiprosessi. Mallissa data on keskiössä, sillä se on kaiken toiminnan lähtökohta, jota aletaan jalostaa liiketoiminnan tehostamiseksi.
Liiketoiminnan ymmärrys. Ensimmäisessä vaiheessa pyritään ymmärtämään liiketoiminnan tarpeita. Tavoite tulee olla tiedossa jo liikkeelle lähtiessä, sillä se ohjaa koko hanketta. Pelkkä datankäsittely itsessään ei tuota mitään uutta tietoa, vaan tarvitaan myös toimialaymmärrystä. Toimeksiantajalla on paras käsitys myös omasta datastaan. Yhteistoiminta ja vuoropuhelu data-analyytikoiden ja toimialan osaajien välillä kehittyy samalla.
Kuva: CRISP-DM-malli
Datan ymmärrys. Mitä tarvittava data on? Mitä tarvitaan liiketoimintaongelman ratkaisemiseksi? Oikean datan tunnistamisen lisäksi täytyy selvittää pääsy dataan ja sen haltuun saaminen, esimerkiksi kuka organisaatiossa tekee teknisen työn datan tuottamiseksi.
Esikäsittely. Data muutetaan hyödynnettävään muotoon. Usein lähtödata on sekalaisessa muodossa. Sieltä voi puuttua arvoja, voi olla epäloogisuuksia, tai voidaan joutua johtamaan uusia arvoja olemassa olevista. Tähän vaiheeseen kuluu usein eniten aikaa hankkeissa.
Mallinnus. Mallinnuksessa ratkaistaan liiketoiminnan tarpeista johdettu ongelma. Usein ongelmat ovat joko numeroarvon ennustamista tai eri asioiden luokittelua. Mallinnus tehdään tavallisimmin koneoppimisen avulla. Myös neuroverkot ja syväoppiminen ovat koneoppimismalleja.
Arviointi. Tehdyn mallinnuksen onnistuminen täytyy voida mitata, jotta sen tuottamaa hyötyä voidaan arvioida. Tulosten esittäminen ymmärrettävästi on oleellista, jotta kaikki organisaatiossa voivat ymmärtää kuinka dataa hyödynnettäisiin liiketoiminnassa.
Käyttöönotto. Rakennettu ennustaja tai luokittelija tulee myös ottaa käyttöön. Tuotantovaiheessa sen täytyy olla toiminnassa jatkuvasti ilman turhia käyttökatkoja, jotka kehitysvaiheessa ovat vielä arkipäivää. Tämä vaihe on enemmän ohjelmistokehitystä, ja voi olla oma hankkeensa saada koneoppimismalli käyttöön.
CRISP-DM-mallissa on tarkoitus jatkaa iteratiivisesti uudelle kierrokselle, sillä ensimmäisellä on syntynyt uutta ymmärrystä dataan. Tämä ymmärrys avaa uusia ideoita ja mahdollisuuksia hyödyntää dataa tai kerätä täysin uutta dataa aiemmin tunnistamattomista lähteistä. Näin organisaation ohjautuvuus datan perusteella paranee koko ajan, samalla kun yhä uusia liiketoimintaongelmia saadaan ratkaistuksi.
Syty datasta: Digitalisaatio ja datan merkitys -webinaarin tallenne on nähtävissä Youtubessa.
Kirjoittaja: Tuomo Sipola, vanhempi tutkija, Jyväskylän ammattikorkeakoulu, IT-instituutti
Tämä blogikirjoitus on osa Tieto tuottamaan -projektin syksyllä 2022 esitettävää Syty datasta -webinaarisarjaa. Webinaarisarjasta voit lukea lisää tästä.
Tieto tuottamaan -projektia rahoittaa Euroopan Unionin aluekehitysrahasto.
Data-analytiikkaa voit opiskella Jamkissa mm. laajassa opintokokonaisuudessa avoimessa ammattikorkeakoulussa. Lue lisää koulutuksesta!