Koneoppimisen hyödyntäminen pienten metallituotteiden laadunvalvonnassa



Pilotoinnin tausta
Pilotointi-idea koneoppimisen hyödyntämiseksi laadunvalvonnassa saatiin yritykseltä, joka valmistaa pieniä monitahoisia metallituotteita. Tällä hetkellä laaduntarkastus tehdään silmämääräisesti pienellä otannalla eräkohtaisesti. Pienten kosmeettisten virheiden lisäksi tuotteet saattavat olla väärän kokoisia ja muotoisia tuotantokoneen vikatilanteitten takia. Tämä saattaa aiheuttaa kokonaisten toimituserien reklamaatiopalautuksia. Tavoitteena yrityksellä on saada tarkastettua jokainen tuote automaattisesti ennen tuotteiden lähettämistä. Tarkastus on haastavaa useiden eri tuotantomallien, suurten erämäärien, useiden tuotantolaitteiden ja materiaalierien laadunvaihteluiden takia.
Tuotteissa ei ole yhtä tiettyä mittaa tai muotoa, mikä saattaa muuttua tuotantolaitteiden vikaantuessa. Tuotantolaitteet sisältävät useita työkaluja, jotka saattavat vikaantua monella eri tavalla. Tämän takia perinteisten ehtopohjaisten konenäköfunktioiden käyttäminen on erittäin haastavaa. Myös materiaali värierot aiheuttavat ongelmatilanteita perinteisille konenäköfunktioille. Tämän takia pilotoinnissa lähdettiin selvittämään, miten koneoppimista pystyttäisiin hyödyntämään tuotteiden laaduntarkastukseen.
Toimenpiteet
Aluksi tehtiin nopea selvitys, millaista kameralaitteistoa ja valonlähdettä kannattaisi käyttää. Kamera ja valonlähdevaihtoehtoina testattiin erilaisia aallonpituusalueita hyödyntäviä laitteistoja UV alueelta lähi-IR alueelle. Kameran suhteen päädyttiin hyödyntämään harmaasävykameraa kustannustehokkuuden takia. Pilotoinnin alusta asti oli selvillä, että opetusdatan keräämistä varten tarvittiin automatisoitu järjestelmä. Kuvien kerääminen manuaalisesti ei ole tehokasta eikä kannattavaa useiden tuotantomallien ja uusien tuotteiden takia. Lisäksi erilaisten vikatilanteiden takia kuvamäärät nousevat nopeasti kymmeniin tuhansiin kuviin. Automaattista opetusdatan keräämistä kokeiltiin aluksi Asyril Asycube -tärymaljalla, jolla syötettiin kuvattavia kappaleita kameran ohi ja kuvat otettiin automaattisesti talteen. Kuva-alueella oli useita tuotteita, jotka leikattiin kuvasta omiksi pienemmiksi kuviksi, jolloin jokainen tuotekuva oli samankokoinen ja kuvassa oli vain yksi tuote. Automaattista tallentamista varten tallennettavat kuvat analysoitiin, ettei kuvassa ole näkyvissä kahta tuotetta tai kappale ole väärässä asennossa. Esimerkkikuvissa on käytetty pieniä pultteja.
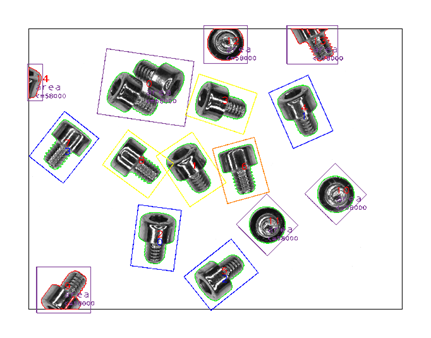
Haasteeksi osoittautui metallikappaleiden heijastukset valaistuksen takia, sekä alustalevyn likaantuminen. Likaantuminen aiheutti taustan tummumista, mikä vaikutti tuotteiden selkeään erottumiseen taustasta.
Kuva-aineiston keräämisen jälkeen on erittäin tärkeää, että aineisto käsitellään huolellisesti. Tämä tarkoittaa sitä, että hyvissä näytteissä saa olla vain hyviä tuotteita ja huonoissa huonoja. Jos kuvat sekoittuvat ja molemmissa aineistoissa on sekaisin kuvia, vaikuttaa se erittäin paljon koneoppimismallin tarkkuuteen. Opetusaineiston käsittelyä varten tehtiin yksinkertainen sovellus, jolla pystyttiin luokittelemaan kuvia erilaisiin luokkiin. Ohjelma annettiin yrityksen ammattilaisille käyttöön ja ensimmäiset kuva-aineistot luokiteltiin yrityksen henkilöstön avulla. Haasteeksi tässä osoittautui kuva-aineiston laajuus ja käytettävä aika kuvien läpikäyntiin. Osa kuvista oli selkeästi vaikeampi luokitella hyviin tai huonoihin, mistä syystä kuva-aineistossa saattoi olla vaihtelua eri henkilöiden tekemien päätösten pohjalta. Toinen iso haaste, joka ohjasi myös seuraavia toimenpiteitä, oli näytteiden kuvaaminen vain yhdestä suunnasta. Kappaleessa saattoi olla pieni virhe, joka jäi kuvaa otettaessa piiloon. Tällöin ns. huonoissa näytteissä saattoi olla iso määrä hyvän näköisiä kuvia.


Aineiston automaattinen kerääminen ilman kuvien luokittelutarvetta
Kuvaamisen haasteiden takia päädyttiin suunnittelemaan kolmen kameran järjestelmä, missä tuotteet lennätettiin kameroiden kuva-alueiden leikkauspisteen kautta hihnakuljettimella. Kuljetinjärjestelmä suunniteltiin myös kappaleidien erottelulaitteistoksi. Eli samaa laitteistoa käytettäisiin sekä kuva-aineiston keräämiseen, että tuote-erien lajitteluun.
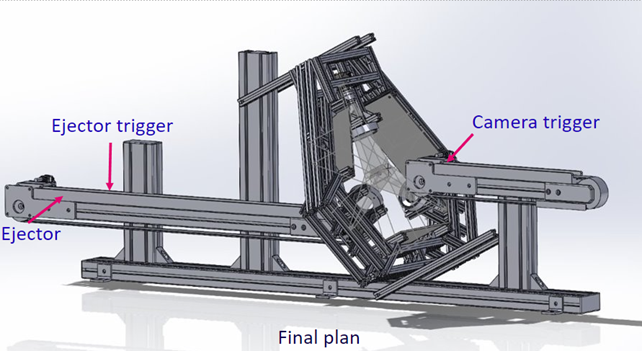
Kuvauksessa käytettiin kolmea harmaasävykameraa, jotka oli kytketty Beckhoff:in logiikkaan. Beckhoff:in ohjelmistosta löytyy Vision-kirjasto, jota voidaan hyödyntää kuvankäsittelyssä. Beckhoff:in järjestelmää oli tarkoitus käyttää sekä kuvaamisessa, analysoinnissa ja erottelussa, mutta koneoppimiskirjastossa ei vielä pilotoinnin aikana ollut hyödynnettävissä CNN-malli, joka on tämän kaltaisessa kuvien analysoinnissa huomattavasti MLP-mallia parempi. Beckhoff:in järjestelmässä voitiin kuitenkin tehdä kuvaus, kuvien rajaus ja tuotteiden poisto linjastolta tarpeen mukaan. Käyttöliittymästä voidaan määritellä millä harmaasävyarvolla ja minkä kokoista kappaletta kuvasta haetaan, sekä minkä kokoinen kuva-alue tunnistetun kappaleen ympärille määritetään.
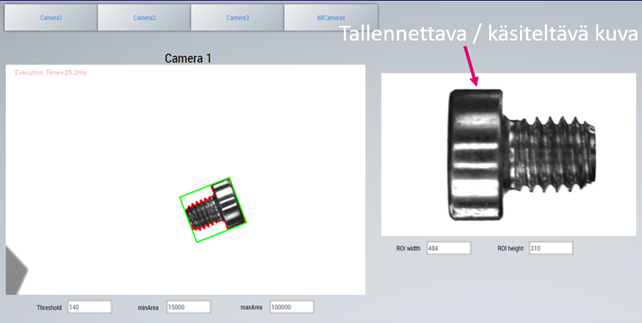
Koska Beckhoff:in järjestelmästä ei vielä löytynyt MLP-mallin hyödyntämismahdollisuutta, päädyttiin mallien opettaminen ja analysointi suorittaa erillisellä tietokoneella Python-ympäristössä. Tämän takia kuvat piti lähettää Beckhoff:in järjestelmästä toiselle tietokoneelle. TwinCAT ADS -kirjastosta löytyi PyAds-rajapinta, minkä avulla laitteiden välinen kommunikointi saatiin toimimaan.
Kuvien tallentaminen
Kappaleidien lentorata oli vaikea saada pysymään vakiona hihnakuljetinta käytettäessä. Kappaleet lähtivät helposti pyörimään ilmalennon aikana ja välillä kappale saattoi alkaa pyörimään kuljettimen pinnalla ja lentää ohi kuva-alueesta. Tämän takia automaattista kuvien automaattiseen kuvientallentamiseen piti lisätä hieman analysointia. Koska annotoinnista haluttiin päästä eroon mahdollisimman tehokkaasti, piti varmistaa, että hyvissä kuvissa ei ole mukana väärässä asennossa tai ohi kuva-alasta lentäneitä tuotteita. Jos yhdestäkin kuvasta havaitaan virhe, tai kappale ei ole kunnolla kuvassa, jätetään kaikista kolmesta kamerasta tulleet kuvat tallentamatta.
Kuva-aineiston tallentamisen jälkeen koneoppimismalli opetettiin Python ympäristössä TensorFlow-kirjastoa hyödyntäen. Malli rakennettiin siten, että kaikista kolmesta kamerasta tulevat kuva yhdistettiin yhdeksi kuvaksi, mikä syötettiin mallille. Näin ollen kappaleessa oleva virhe erotetaan, vaikka vikatilanne olisi nähtävissä vain yhdestä suunnasta kappaletta katsottaessa. Olettaen tässä vaiheessa, että vikatilanne on kappaleen sivulta havaittavissa (ei päätyvikoja).
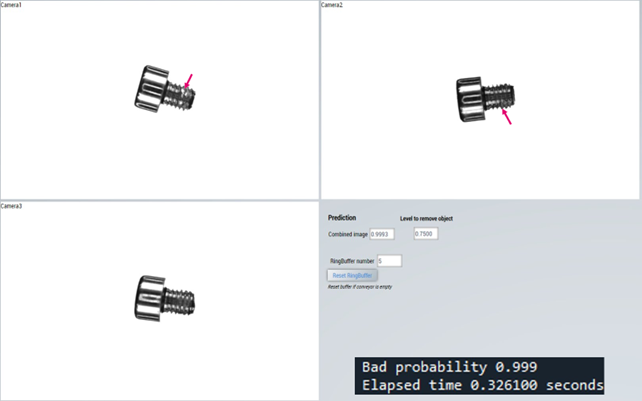
Laitteistoa voidaan siis käyttää sekä kuva-aineiston keräämiseen, että kappaleidien laadunvalvontaan. Beckhoff:in ympäristöstä määritellään, millaista kuvaa ja kuva-aluetta halutaan käyttää ja Python ympäristön puolelta valitaan ohjelma sen mukaan, halutaanko kuvia tallentaa, vai tehdä laadunvalvontaa. Jos koneoppimismallin tunnistus huonoksi tuotteeksi on yli operaattorin määrittelemän raja-arvon, puhalletaan tuote pois linjastolta. Poistoa varten Beckhoffin järjestelmään lisättiin rengasbufferi, johon tallentuu jokaisen kuvatun tuotteen numeerinen arvo koneoppimismallilta. Näin ollen jälkimmäisellä kuljettimella voi olla useita kuvattuja ja analysoituja tuotteita, joiden arvo luetaan bufferista, kun tuote tulee paineilmasuuttimen kohdalle.

Koneoppimismallin rakenne ja koulutus
Kuvaluokittelumalliksi valittiin Xception-arkkitehtuurin konvoluutioneuroverkko. Mallille annetaan syötteeksi kappaleen kuvat kolmesta eri suunnasta. Neuroverkko luokittelee kuvan kahteen luokkaan: virheetön tai valmistusviallinen. Malli tuottaa myös todennäköisyysarvion jokaiselle tekemälleen luokittelulle. Tällä tavalla käyttäjä saa myös tietoa siitä, kuinka varma tekoäly on tekemästään luokittelusta.

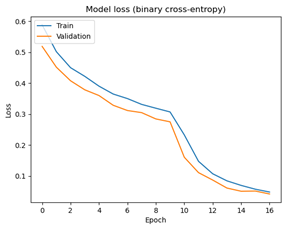
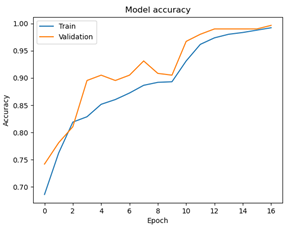
Käytettävissä oleva kuva-aineisto koostui 1223 kuvasta. Aineisto jaettiin satunnaisesti opetus- ja validointiosiin siten, että opetusaineistossa oli 917 kuvaa ja validointiaineistossa 306 kuvaa. Koneoppimismalli koulutettiin opetusaineiston kuvilla ja sen tarkkuus validoitiin validointiaineiston kuvilla. Opetusprosessissa minimoitiin kustannusfunktiota (binary cross-entropy) numeerisella Adam-algoritmilla 16 iteraatiota. Alla olevissa kuvissa näkyy kustannusfunktion (loss) ja mallin tarkkuuden (accuracy) kehitys opetusprosessin aikana. Kuvaajista näkyy, ettei malli ylisovitu koulutuksen aikana ja että lopullisen mallin luokittelutarkkuus validointiaineistossa on n. 99.7 %.
Alla näkyy kaksi esimerkkiä koneoppimismallin tekemästä luokittelusta. Vasemman puoleisen kappaleen malli luokittelee virheettömäksi pultiksi (99.7 % todennäköisyydellä), ja oikean puoleisen kappaleen malli luokittelee valmistusvirheelliseksi (99.9 % todennäköisyydellä). Molemmat luokittelut menivät näissä esimerkeissä oikein.
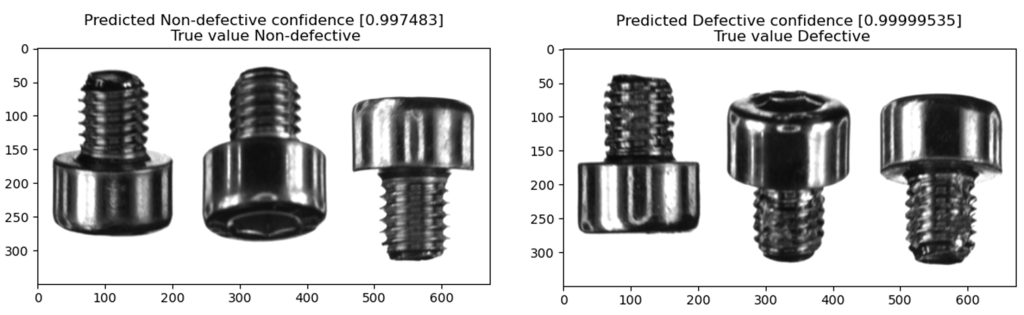
Alla olevassa kuvassa näkyy vielä mallin ainut virheellinen luokittelu validointiaineistossa. Koneoppimismalli luokittelee kuvan virheettömäksi (99.3 % todennäköisyydellä), mutta ihminen on kuitenkin luokitellut tämän valmistusvirheelliseksi pultiksi. Osoittautui kuitenkin, että kyseessä on ihmisen tekemä virhe, sillä kuvassa ei ole näkyvissä minkäänlaista valmistusvikaa. Näin ollen projektissa koulutetun koneoppimismallin tarkkuus on todellisuudessa täydet 100 % validointiaineistossa.

Prosessointiajat
Kuvien analysointi suoritettiin tietokoneella, jossa oli RTX3060 näytönohjain. Kuvaamiseen ja kuvan rajaamiseen kului aikaa n. 13ms ja kuvien analysointiin koneoppimismallilla kului aikaa n. 300ms.
Vastaavasti pelkkää prosessoria hyödynnettäessä aikaa kului kuvaamiseen n. 20ms ja analysointiin koneoppimismallilla n. 600ms.
Muistin käyttö
Koneoppimismallien opettaminen saattaa vaatia yllättäviä määriä muistia. Varsinkin kuva-aineiston kasvaessa saattaa tietokoneen keskusmuisti loppua kesken. Pilotoinnissa oli esimerkiksi n. 1200 kuvaa, joiden resoluutio oli 672*350px (kolmen kameran yhdistetty kuva). Kansioon tallennettuna kuva-aineisto on vain alle 250Mb, mutta koneoppimismalline opetuksen yhteydessä keskusmuistin tarve kasvaa yli 7Gb. Opetuksen jälkeen järjestelmä tarvitsee vielä yli 2.2Gb muistia, eli yhteensä tarvittava muistimäärä on yli 9Gb.
Esimerkkitapauksessa kuva-aineisto on varsin pieni, joten muistin käyttö saattaa olla huomattavasti tätä suurempi.
Esimerkki muistinkäytöstä koneoppimismallissa:
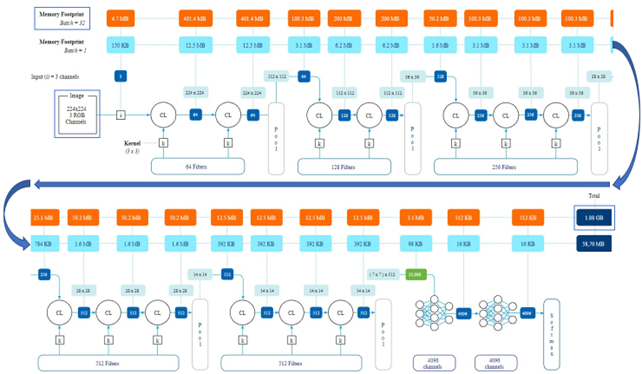
Resource: Frank Denneman, Trainin vs Inference – Memory consumption by neural networks. July 15, 2022. https://frankdenneman.nl/2022/07/15/training-vs-inference-memory-consumption-by-neural-networks/
Pilotointi toteutettiin osana coADDVA -hanketta. Hanke tehostaa keskisuomalaisten valmistavaan tuotantoon ja kunnossapitoon keskittyvien pk-yritysten toimintaa nopeaa laskentaa hyödyntäen. coADDVA – ADDing VAlue by Computing in Manufacturing -hanketta rahoittaa Euroopan unionin aluekehitysrahasto (EAKR). REACT-EU-hankkeet rahoitetaan osana Euroopan unionin COVID-19-pandemian johdosta toteuttamia toimia.
Kirjoittajat:
Samppa Alanen, asiantuntija, Jyväskylän ammattikorkeakoulu
Tomi Nieminen, lehtori, Jyväskylän ammattikorkeakoulu