Data-alan termit haltuun

Data-alan termit ovat nykyään usein esillä ja uusia syntyy koko ajan. Alla avataan muutamia keskeisimpiä käsitteitä, joiden tunteminen voi helpottaa alan ymmärtämistä.
Tekoäly (artificial intelligence) itsessään ei ole uutta. Päätöksiin ja ennusteisiin kykeneviä ohjelmistoja on pyritty rakentamaan informaatioteknologian alkuajoista lähtien. Ihmisetkin tekevät maailmassa toimiessaan päätöksiä ja ennusteita tietoisesti ja tiedostamatta koko ajan, joten tekoälyn voidaan ajatella tekevän samankaltaisia päätöksiä. Tekoälyn menetelmät, joita hyödynnetään nykypäivänäkin sovelluksissa, ovat lähtöisin jo 1950-luvulta.
Koneoppimisen (machine learning) menetelmissä lähtöaineistona on data, josta algoritmin eli eräänlaisen toimintaohjeen avulla voidaan opettaa tekoäly toimimaan järkevällä tavalla tekemään päätöksiä ja ennusteita. Näitä mentelmiä voi löytää nykymaailmasta tuotantokäytössä. Data on kuitenkin oleellinen osa, jotta on jotain, jonka pohjalta oppia. Dataa voidaan ajatella esimerkkeinä ongelmasta, joka pitää ratkaista. Näiden esimerkkien avulla koneoppimisalgoritmi oppii tekemään päätöksiä ja ratkaisemaan ongelman.
Syväoppimisen (deep learning) menetelmät yrittävät jäljitellä ihmisten aivojen rakennetta ja toimintaperiaatteita. Neurotieteiden nopean kehityksen takia pystytään mallintamaan yksinkertaistettu jäljitelmä ihmisen aivojen rakenteesta ja toimintaperiaatteista. Keinotekoiset neuroverkot koostuvat joukosta yksinkertaisia solmuja eli keinotekoisia neuroneita, joiden välillä on liitoksia. Yhdessä ne muodostavat neuroverkon hieman kuin ihmisen aivoissa. Tällaista neuroverkkoa opetetaan datan avulla kuten mitä tahansa koneoppimisen menetelmää. Viime vuosina laskentakapasiteetin nopean kehityksen ja datan määrän kasvun takia neuroverkkojen suosio on kasvanut räjähdysmäisesti.
Mitä tekoäly vaatii? Tekoälyn käyttöönotto vaatii dataa, osaamista, laskentakapasiteettia ja ennenkaikkea uskallusta ja aikaa. Dataa pitää olla riittävästi ja sen täytyy olla tarpeeksi hyvälaatuista, jotta tekoälyn menetelmät on mahdollista saada luotettaviksi. Jos dataa ei ole tarpeeksi, niin sitä pitää alkaa keräämään. Tekoälymenetelmien osaaminen voi olla yrityksissä yksi puuttuva tekijä, mutta kouluttautuminen tai osaamisen ostaminen tekoälyyn keskittyneiltä yrityksiltä on mahdollista. Myös korkeakoulujen kanssa tehty yhteistyö erilaisissa hankkeissa voi olla avuksi. Tekoälyn kouluttaminen vaatii laskentakapasiteettia, jota on mahdollista ostaa pilvipalvelutarjoajilta tai itse investoida laskentapalvelimeen.
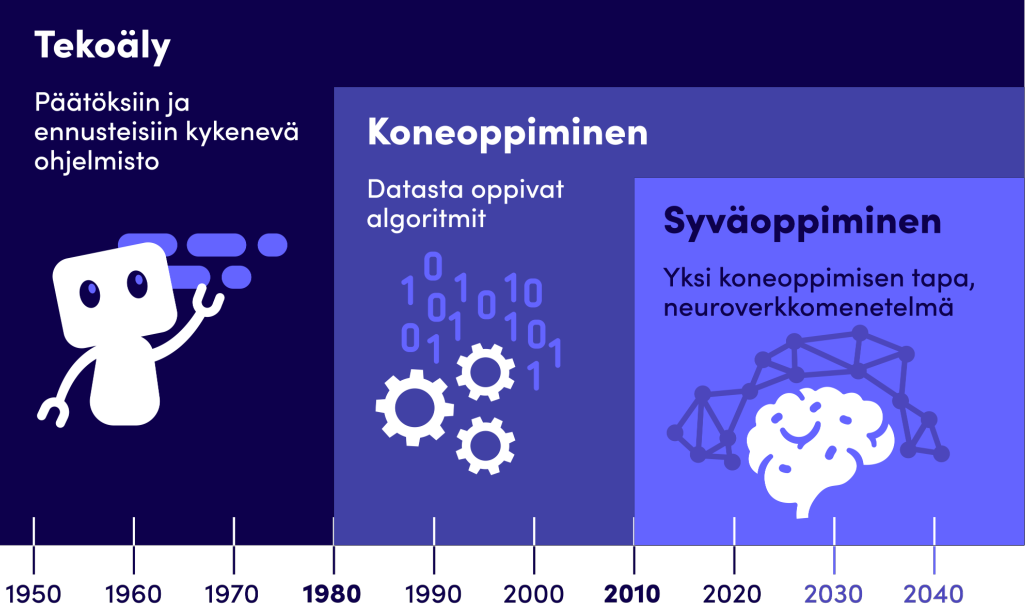
Kuva: Tekoäly ei ole uutta. Pohjautuen: Awais Bajwa (2019). 70 years history of AI. Towards Data Science.
Heikko kapea tekoäly (weak/narrow artificial intelligence) on hyvä yhdessä sille opetetussa asiassa. Tekoäly suoriutuu siinä yhdessä tehtävässä hyvin, usein jopa ihmistä tarkemmin. Muuta se ei sitten osaakaan tehdä. Nykypäivän tekoälyt ovat kaikki heikkoja. Esimerkiksi šakkipelin tietokonevastustaja edustaa heikkoa tekoälyä. Pelissä on rajoitettu säännöstö, jolloin tekoäly voi ratkaista rajoitetun ongelman. Myös aasialaisessa go-lautapelissä on nykyään hyviä tekoälyjä. Kuvantunnistus on myös hyvä esimerkki heikosta tekoälystä. Jos kuvantunnistin opetetaan luokittelemaan kissojen ja koirien kuvia, se on silti kykenemätön tunnistamaan hevosta kuvasta.
Vahva tekoäly (strong artificial intelligence) lähestyy ihmisen älykkyyden tasoa. Hyvänä kiinnekohtana toimivat tieteiskirjallisuuden robotit, joilla on ihmisen kaltainen äly. Laajojen taustatietojen soveltaminen tulee oleelliseksi, sillä maailma, jossa elämme, on laaja ja pelkästään selviytyminen vaatii monimutkaista toimintaa. Edes ihmisen tason saavuttaminen monissa arkipäivän asioissa, joihin ihminen pystyy, on yhä kaukainen tavoite. Nykyajan chat-botit ja japanilaiset humanoidirobotit ovat yhä hyvin rajoittuneita.
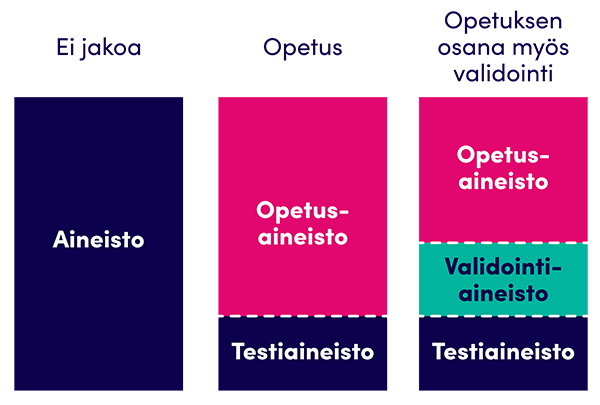
Kuva: Aineiston jakaminen koneoppimista varten.
Opetusaineisto ja testiaineisto (training set, test set). Tekoälyä opetettaessa algoritmille syötetään dataa, jonka pohjalta tehdään haluttuja päätelmiä. Data täytyy jakaa kahteen osaan: opetus- ja testiaineistoon. Opetusaineiston avulla valittu koneoppimisalgoritmi opetetaan ymmärtämään kaikki se, mistä osista valittu data koostuu ja mitkä asiat liittyvät tai korreloivat toisiinsa. Testiaineston avulla testataan lopuksi, kuinka hyvin algoritmi kykenee syötetyn datan pohjalta tekemään päätelmiä sovitun virhemarginaalin puitteissa. Aineiston jako tehdään satunnaisesti esimerkiksi jakamalla data opetusaineiston ollessa 70-80% ja testiaineiston 30-20%. Opetusaineistossa olevaa dataa ei siis käytetä testiaineostossa.
Datan käsittelyyn ja koneoppimiseen liittyy paljon termejä, jotka voivat olla hyvinkin teknisiä. Muutamien peruskäsitteiden tunnistaminen kuitenkin auttaa ymmärtämään nykyään käytävää keskustelua tekoälyn kehittymisestä.
Syty datasta: Data alan termit haltuun -webinaarin tallenne on nähtävissä Youtubessa.
Kirjoittajat:
Tuomo Sipola, vanhempi tutkija, Jyväskylän ammattikorkeakoulu, IT-instituutti
Mika Rantonen, yliopettaja, Jyväskylän ammattikorkeakoulu, IT-instituutti
Tämä blogikirjoitus on osa Tieto tuottamaan -projektin syksyllä 2022 esitettävää Syty datasta -webinaarisarjaa. Webinaarisarjasta voit lukea lisää tästä.
Tieto tuottamaan -projektia rahoittaa Euroopan Unionin aluekehitysrahasto.
Data-analytiikkaa voit opiskella Jamkissa mm. laajassa opintokokonaisuudessa avoimessa ammattikorkeakoulussa. Lue lisää koulutuksesta!


